Sammanfattning
Så här avgör du om din PDF är raster- eller vektorbaserad och hur detta påverkar förmågan att fästa mot ett objekt eller välja text.
Relevanta produkter
Revu® för Windows® och Revu för Mac®
Problem
- Du kan inte fästa mot ett objekt när du gör mätningar.
- Du kan inte redigera text med hjälp av Redigera > PDF-innehåll > Redigera text
 .
. - Du kan inte välja eller söka efter text.
Varför händer detta?
Anledningen till att de här problemen inträffar är att alla PDF-filer inte är skapade på samma sätt. Vissa PDF:er innehåller mer information än andra, även om det vid första anblicken inte går att se skillnad på dem.
Det kan se ut som att sidan innehåller linjer och tecken, men det är inte säkert att de underliggande delarna som representerar dem i PDF:en är vektorlinjer och textdelar, vilka behövs för att fästa mot innehåll och söka efter samt välja text.
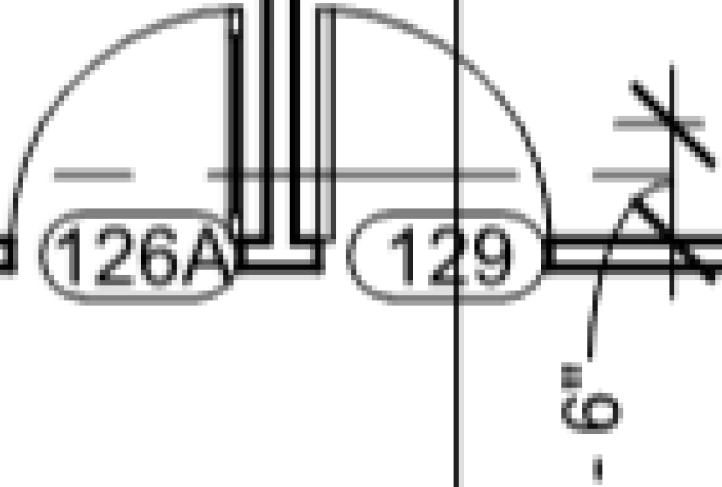
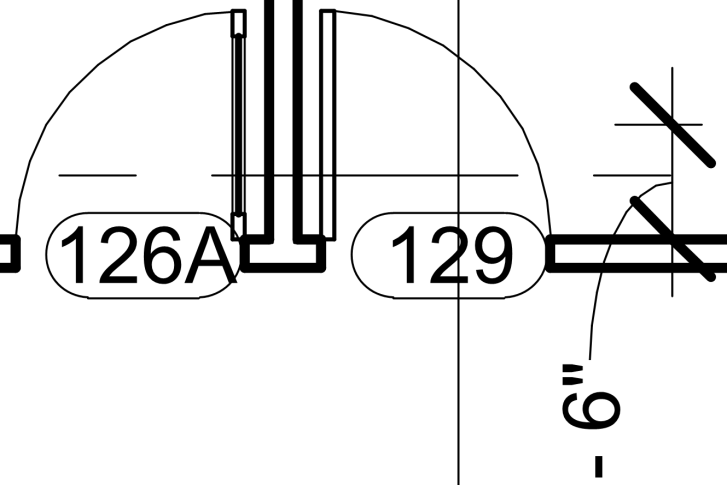
Jämförelse av raster- och vektorinnehåll
Låt oss titta på skillnaden mellan raster- och vektorinnehåll i en PDF.
| Raster-PDF | Vektor-PDF |
 |
 |
Raster
En rasterbild skapas med hjälp av en rad fyrkantiga punkter som kallas pixlar. Ett exempel på en raster-PDF är en fil som har skapats genom att skanna in ett papper. En skannad PDF skapas genom att man gör en bitmap-bild (som en JPEG eller TIFF) av den aktuella sidan och placerar bilden på PDF-sidan. Det innebär att en skannad PDF eller raster-PDF bara innehåller ett rutnät av punkter som ser ut som linjer och text – den innehåller inte några riktiga linjer eller text som en dator kan känna igen. Därför finns det inga linjer för Snap mot innehåll-funktionen att fästa mot, och ingen text att välja eller söka i.
För att avgöra om en PDF är en rasterbild eller skannad bild zoomar du in nära. Linjerna och tecknen på sidan ändras antingen till ett rutnät av fyrkantiga punkter eller blir suddiga.
Vektor
En vektorbaserad PDF använder linjesegment för att definiera all geometri på sidan. De flesta PDF:er som skapas från CAD (Computer-Aided Design) är vektorbaserade. Vektor-PDF:er är oftast att föredra framför raster-PDF:er eftersom de innehåller mer data, vilket gör dem enklare att arbeta med. Du bör alltid försöka arbeta med vektor-PDF:er som skapats från källan istället för att skapa PDF:er från skanning.
Fördelen med en vektor-PDF är att geometrin blir tydlig även när du zoomar in för att se detaljer i ritningen. Mätningar och mängdavtagningar (samt kalibreringen av dessa) är precisa i en vektor-PDF eftersom du kan använda Snap mot innehåll för att fästa mot vektorlinjerna i PDF:en.
Text
Text är en särskild typ av PDF-innehåll. Du kanske ser texttecken i PDF:en, men det är inte säkert att de här tecknen faktiskt är PDF-textelement. Texten kan istället bestå av rasterpunkter eller vektorlinjesegment. Även om de här elementen ser ut som text innehåller de inte de data som gör att en dator kan känna igen dem som text. Den här typen av ”text” är egentligen en slags bild, som inte går att välja, söka i eller redigera.
Innan vi går in på detaljer finns det ett snabbt test som du kan göra för att ta reda på om din PDF innehåller text. Från menyraden går du till Redigera > PDF-innehåll > Välj all text (i Revu 2017 eller tidigare går du till Redigera > Välj > Välj all text ). All text i PDF-filen ska nu vara markerad i blått. Om tecknen inte markeras i blått är de i själva verket en raster- eller vektorbild.
- PDF-textelement (eller riktig text) – är alltid att föredra i en PDF eftersom det ger ett mer dynamiskt innehåll. PDF:er som är skapade i teckenbaserade program (t.ex. Word® och Excel®) innehåller nästan alltid riktig text. När du zoomar in på texten ser tecknens kanter alltid skarpa och tydliga ut – oavsett hur nära du zoomar in. Texten är sökbar och kan alltid väljas.
- Text från optisk teckenläsning (OCR) – genom att köra OCR (endast för Revu eXtreme) kan raster- och vektorbilder översättas till sökbara data. OCR tolkar med andra ord bilderna i en skannad PDF och skapar ett osynligt textlager ovanpå dem. Det är det här lagret som gör att du kan söka, välja och markera bilder som inte innehåller riktig text.
- Vektortecken – skapas av linjesegment som används för att rita varje teckens form. Det här gäller vanligtvis om PDF-filen har skapats från CAD (ofta AutoCAD®) eller om ett teckensnitt av en annan typ än TrueType har använts.
- Varför använder CAD inte TrueType-teckensnitt för att skapa riktigt text? Det beror på att AutoCAD är äldre än Macintosh®, Windows® och TrueType-teckensnitt. Därför behövde man skapa ett eget teckensnittssystem, som kallas SHX. SHX-teckensnitt definieras genom linjesegment. Linjesegmenten översätts till PDF-filen istället för textdata.
- True Type-teckensnitt i CAD är att föredra när du skapar PDF:er. Bluebeam-pluginprogrammet för AutoCAD konverterar automatiskt True Type-teckensnitt till sökbar text.
- Vektortecken kännetecknas av ett ojämnt utseende om man zoomar in på dem. Dessa ojämnheter skapas av de linjesegment som varje tecken består av.
- Program för grafisk formgivning (t.ex. Adobe Illustrator®) skapar också vektortecken. Men dessa vektortecken har tydliga, skarpa kanter om man zoomar in på dem.
- Rastertecken – som tidigare nämnts används enskilda pixlar för att definiera varje tecken.

Mer information
AutoCAD: skapa PDF:er med sökbar text – lär dig hur du skapar sökbara PDF-filer från AutoCAD.
Instruktioner
Revu 2017 och tidigare
Revu 2018
Revu 2019
Revu för Mac 2
Revu för Mac 1
Dokumentbearbetning